Create a Cross-Region Active-Active Application on Alibaba Cloud
Consider the following situation. You are a race-car driver and your car is at the starting line. Your helmet is on and you already heated up your tires. Then, you look to your left, and the driver next to you is using not one, but two cars. He somehow managed to synchronize the pedals and the steering wheels on both vehicles. You are so puzzled about the situation that you feel the need to lower the window and ask him, “Pardon me… why are you using two cars instead of one?”. His reply just melts your face, “Because I want to be sure that, if one of the cars fails, I can still finish the race”.
Hey, welcome to the paranoid world of data storage!
Well, jokes aside, the above situation is just a funny representation of what we, solution architects, like to do when dealing with systems where data is the central and biggest asset. At the end of the day, we end up driving 2 cars at the same time quite efficiently in our applications.
What’s the Active-Active Architecture
At the end of the day, redundancy is what keeps systems running with a degree of reliability, but this does come at the cost of being more pricey. Depending on our approach of how to duplicate or triplicate (or more) our resources, our architecture will get a different name. In this article we will focus on the Active-Active architecture, where all the moving parts will be exposed and accessed from the production application, but at the same time keeping uptime and being failure tolerant.
This article will focus on High Availability and reliable systems. This is about keeping downtime lower than normal. Some critical platforms like the ones made for hospitals and datacenters can’t afford downtime at all, as unavailability will actually impact people’s lives.
These types of systems are designed on top of some principles like “no single point failures” or “failure detection”, where a lot of engineers’ time is used to think and continuously improve the reliability of a platform. It tries to reduce to a minimum the amount of critical pieces that, if they fail, the whole system falls. Think of this as your home router, you can own a great NAS, a long-lasting UPS, a great CAT7 cabling and other bunch of shiny things. If the route fails, everything will render useless. The “no single point failures” approach will recommend you to have 2 internet connections with 2 different routers. See where I’m coming from now?
Why Would I Need to Build My Application Like This?
The explanation of why your application would need it goes from lowering end-users latency, improving disaster recoveries to a bunch of other obscure and/or logical business requirements. But, in a nutshell, it protects your data while keeping your application running.
Some of you may wonder why an Active/Active architecture is better than an Active/Passive. At the end, both provide good resilience to failure. And yes, you are right. But in an Active/Passive architecture 50% of the resources are just idle, waiting. Instead, in an Active/Active architecture you will get the benefit of using all of the resources at the same time, increasing with this the speed and reliability of the platform built on top of this.
I’m not saying that Active/Active is necessarily better than Active/Passive, as some business needs will require the second to be in place. From my point of view, Active/Active is just the overall better architecture to use for most of situations out there.
Okay, Let’s Get Down to It
To make things easier for you, I wrote this article including some drawings to set up a very basic Active/Active database and two ECS Instances.
The idea here is to create one VPC in one region, with an ECS instance and the Master RDS database. Then, create an express connection with another VPC in a different region where another ECS is located and the Replica Read RDS database.
By default, each ECS will connect to the nearest RDS but, in the case of DB failure, the traffic will be routed to the other available one, bringing downtime down to virtually nothing.
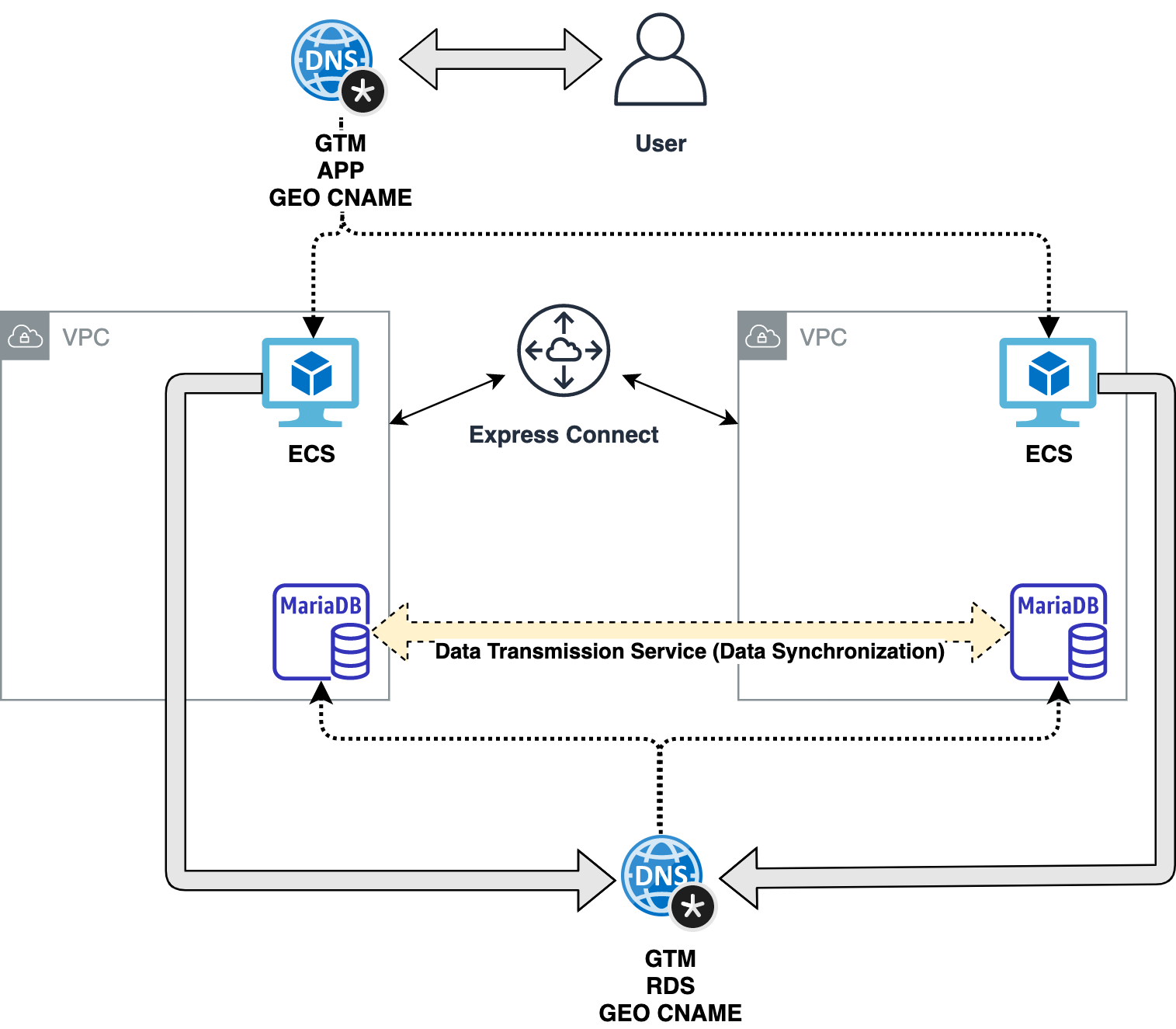
As you can see in the diagram above, the most important piece is the Global Traffic Manager (GTM), an excellent Alibaba Cloud tool where you can create DNS records that, based on the geographical location (Geo DNS) of the requester (ECS or Visitor), returns different values. If the GTM detects failure in the response, it supports DNS Failover and will answer with a second option or a defined “default” one.
All you need to do to make it work is to update the DNS records for your endpoints and apply the CNAME that GTM creates, the rest is taken care of by Alibaba Cloud. To keep in sync the 2 RDS instances, you’ll need to leverage Data Transmission Service (DTS) in “Data Synchronization” mode.
From here, both ECS instances and Visitors will get routed automatically to the nearest resource while keeping everything in sync and failure resistant.
Conclusion
After this mini-tutorial, I hope you have begun to understand some of the intricacies of High Availability, Active/Active architectures and general system resilience. Think of this as the beginning of your journey to be a better Solutions Architect or SRE. Remember, if you have any questions on how to run this example, please post all your questions on the official Alibaba Cloud forum.
Republished from: Create a Cross-Region Active-Active Application on Alibaba Cloud.